基于深度强化学习的人机协作组装任务分配
时间: 分类:教育论文 浏览次数:
摘要:为适应人机协作组装任务分配日趋复杂的任务结构和高维的任务状态空间,提出了一种基于深度强化学习的人机协作组装任务分配方法。首先,将人机协作组装任务分配形式化为强化学习问题,设计了通道帧图进行任务分配环境状态的表示,并构建了通用化的组装闯关游戏模拟环境。其次,为解决DQN(DeepQNetworks)算法频繁的情节重启导致探索效率低下的问题,提出了存档机制及其改进算法ArchiveDDQN(DoubleDQN),并介绍了利用该算法与模拟环境交互以进行人机协作组装任务分配的流程方法。最后,通过种不同难度的组装模拟环境进行对比实验,验证了所提出方法的有效性。
关键词:深度强化学习;存档机制;人机协作;任务分配;生产组装
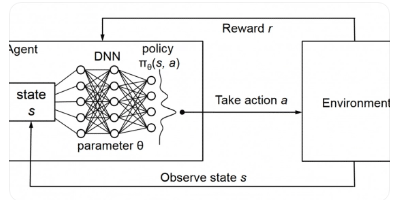
0引言
自1990年以来,制造业中的人机协作(RC,Humanrobotcollaboration)得到了广泛的研究和关注[14]。工业4.0的推行,人机协作成为制造业中主要的网络物理技术和促成技术之一[5,6],利用人机协作的工业应用数量迅速增长7]。其中,组装是人机协作最有趣和最有前景的应用场景之一8]。在人机协作组装的工业设计中,任务分配决定着人和机器人的工作内容和执行顺序,深刻影响着人机协作的流畅性和生产系统的效率,是当前学界研究的热点之一。传统的人机协作组装任务分配方法通常将问题形式化为带约束的组合优化问题,并通过算法进行优化以实现特定目标利益的最大化10。
LAMON等11以任务复杂性、灵巧性和工作量为组合指标,提出了一种离线分配算法,可以将任务最佳地分配给工作单元,并在金属结构的概念协作组装中进行了验证。WANG等12设计了包含时间消耗和人工的协作成本函数,并开发了启发式行动计划算法优化成本函数,从而生成最优的组装任务分配方案。JOHANNSMEIER等13将人和机器人的差异特殊性转移到不同的成本函数中,并基于方法定义了一种启发式算法优化人机协作组装成本。
孔繁森等14以资源利用均衡率、工人操作复杂度均衡率、平均决策过程复杂度为约束条件,以最小化平衡滞延时间为目标,并使用遗传算法优化得到人机协作组装任务分配最佳方案。传统的组合优化方法主要针对简单的任务结构和极小的任务空间,并未考虑人和机器人均可执行的操作,缺乏灵活性和通用性。随着人机协作技术的发展,组装任务的结构将变得愈加复杂(如人机并行执行共享任务),任务空间也愈加庞大(如多个工人和多个机器人)。在充分考虑必要的人和机器人信息以及组装约束条件下,人机协作组装任务分配将具有高维复杂的状态空间,这是传统的组合优化方法难以解决的。近年来,随着物联网(IOT,InternetofThings)的发展,大数据处理方法如广域存储与计算协同调度15、移动边缘计算16等有利于实现更高效率的大规模人机协作组装任务分配。
值得注意的是,深度学习和强化学习技术在处理高维复杂空间问题和大规模决策问题上表现出日益显著的优势,为克服传统任务分配方法的局限性提供了新的方向。如ZHEYUAN等[17]开发了一种新的基于深度图注意网络的分配算法来自动学习分配问题的特征,在测试中约的任务分配问题找到了高质量的任务分配方案。等[18]通过将人机协作组装过程格式化为具有映射规则和游戏规则的组装棋盘,并使用基于强化学习的自演算算法实现了可调节高度的办公桌组装案例的最佳任务分配。
随后,在组装棋盘的基础上,等[19]采用基于深度强化学习算法DQN(DeepQNetworks)的多智能体强化学习MARLMultigenteinforcementearning方法求解任务分配策略,并通过组装案例验证了该方法在不同任务数和智能体数下的有效性。受上述研究的启发,结合华晨宝马搭建智能白车身生产系统的项目需求,本文提出了一种基于深度强化学习的人机协作组装任务分配方法。
本文首先将人机协作组装任务进行问题建模,并构建闯关游戏形式的通用化强化学习求解环境。区别于文献18]和19]的组装棋盘,本文设计了通道帧图来表示任务分配的环境状态,这种格式不仅能更清晰地反映高维复杂任务分配环境的状态信息,而且可以直接转化为数字张量输入到深度神经网络以便于深度强化学习算法的求解。在该组装闯关游戏模拟环境中,DQN系列算法可以在没有任何指导的情况下从初始状态开始执行任务分配动作。然而,在训练过程中,现有的DQN算法容易遭遇错误动作,导致频繁的情节重启。在实现完整的任务分配之前,算法容易陷入困境。因此,本文开发了存档机制,以提升算法的探索效率并改善经验池回放基准。同时,本文还提供了存档机制的两种应用模式及其改进算法ArchiveDDQN,以进一步提升算法的性能,实现更高效的人机协作组装任务分配。
1.人机协作组装任务分配问题建模
1.1问题描述
人机协组装作任务通常可以按照三个主要步骤进行实施。首先是任务分解,即将一个组装任务拆分成一定数量的子任务。其次是任务排序,根据实际的需求和约束等将子任务按照一定的先后顺序进行排列。最后也是最关键的是任务分配,需要根据子任务特征来进行工作负荷分配,以充分发挥工人和协作机器人的各自优势,提高生产效率。在华晨宝马搭建智能白车身生产系统这一项目中,需要在项目前期自动生成最优的人机协作组装任务分配序列,为人机协作生产工位的快速布置和规划提供指导。为了清晰地描述人机协作组装任务过程,使用该项目中一组前端模块支架的人机协作组装任务进行演示。
(1)任务分解。该组装任务的目的是通过前表面和上表面的螺栓组(由螺栓和垫片组成)来连接支架零件。前表面朝上时,先放置个螺栓组(B1~B4),然后拧紧螺栓。接着通过翻转使上表面朝上,工作内容与前表面一致。该任务被分解为18个子任务,如表所示。根据任务的物理特性和工作单元的操作特性,子任务可以分为三种类型,类(仅适合人),类II(仅适合机器人),类III(通用型任务,适合人和机器人)。例如,人可以轻松地拾取螺栓组合,并精准地将螺栓旋入带螺纹的孔中。
但是,这个任务对于机器人来说可能需要花费非常高昂的代价。类似的,使用机器人拧紧螺栓速度更快且可以保证稳定的预紧力。此外,有些任务是通用的,如翻转支架没有太高的约束要求,分配给人和机器人都是可以的。值得一提的是,这类通用型的任务分配给人或者机器人的执行时间可能是不一样的。因此,可将时间项按工作单元类型进行划分。
(2)任务排序。对于组装任务,其子任务的执行顺序是受组装条件限制的,如产品设计、质量控制、物理约束等。因此,有些子任务之间存在顺序约束。例如,必须先放置了螺栓组合才可以去拧紧。相反,有些子任务之间没有顺序约束,如先放置哪个螺栓组合。此外,放置完一个螺栓组合就立即执行拧紧操作也是允许的。为了规范组装顺序,在本案例中,将同一个工作面上的所有螺栓组合放置好之后再执行拧紧操作。为了清晰地表述子任务之间的顺序约束,设计了关系联络矩阵。其中,第一行和第一列为子任务的编号。编号
(3)任务分配。一般而言,任务排序受到的限制条件是相对宽松的,这意味着子任务的具体执行顺序存在很多可能性。这无疑增加了任务分配的难度。同时,任务分配还要考虑子任务的属性和工作单元的负载平衡,以实现最大化的工作效率。其中很重要的一点就是决定通用型任务到底分配给人还是机器人更合适。
1.2形式化强化学习
将人机协作组装任务分配形式化为一般的强化学习,可以为问题求解提供极大的便利。
2以存档机制改进的算法ArchiveDDQN
2.1存档机制及其原理
在深度强化学习算法中,由MNIH等20,2提出的DQN算法,在处理高维的状态空间问题上展现出巨大的优势。近年来,DQN得到了极大的改进和拓展[2,在多种Atati游戏中都取得了超越人类平均水平的成绩。在人机协作组装闯关游戏环境中,DQN系列算法可以从零开始通过不断自学习获得最优的任务分配策略从而完成闯关游戏。但在训练的早期阶段,由于QN深度近似网络权重参数初始化的随机性和深度近似网络拟合能力的不确定性,算法十分容易产生错误的分配动作,导致闯关失败从而使游戏情节频繁重启。现实中的许多闯关游戏都设置了功能选项进行存档,在终结或者中途退出后,游戏可以通过重载存档继续进行。
2.2存档机制应用模式及其改进算法
根据存档机制的特点,本文提出了两种存档机制的应用模式,分别是普通模式存档机制(Archiveormalmode,Archive)和通关模式存档机制(rchiverushmod,Archive)。顾名思义,普通模式就是在
此外,通关模式存档机制Archive能保证所有子任务均能得到分配,避免了任务分配失败。VANHASSELT等人25改进的DoubleDQN(DDQN)学习算法,通过两个网络分别进行学习解决了学习中因最大化偏置导致的状态值被过度估计的问题。因此,本文在DQN的基础上,提出了以存档机制改进的算法ArchiveDQN。
3利用ArchiveDDQN进行任务分配
3.1ArchiveDDQN算法训练和测试
在获取人机协作组装任务分配策略和最优方案之前,需要使用人机协作组装闯关游戏模拟环境对ArchiveDDQN算法的智能体进行训练和测试。
在训练过程中,组装闯关游戏模拟环境和ArchiveDDQN算法之间需要进行实时交互。首先,执行环境将环境状态输出,并转换为张量输入到算法的近似网络。算法智能体得出分配动作后由模拟环境执行分配动作,然后输出新的环境状态和奖励。然后对每一次获得的分配动作、环境状态和奖励进行统一格式并存入经验池。最后通过小批量随机采样抽取经验池中的经验数据对智能体进行训练,从而不断改进智能体的任务分配策略。在进行测试时,需要先获取训练过程得到的深度网络权重参数,然后加载到深度近似网络。与训练过程不同的是,测试过程不进行经验回放和小批量采样训练,智能体的任务分配策略是固定不变的。
3.2获取最优任务分配策略和分配方案
通过训练和测试对比,可以获得最优的任务分配策略。在应用ArchiveDDQN算法进行人机协作组装任务分配时,只需将最优任务分配策略对应的深度网络权重参数加载到算法的深度近似网络即可。
在任务分配过程中,组装闯关游戏模拟环境与ArchiveDDQN算法是实时交互的,面对任意的模拟环境状态,ArchiveDDQN算法均能以最优任务分配策略轻松获得下一步的最优任务分配动作,这对于拓展到动态任务分配是十分有利的。通过整理模拟环境和算法的输出信息,可快速获得最优任务分配方案。组装闯关游戏模拟环境与ArchiveDDQN算法之间的交互是按情节划分的,通过将单一情节的分配动作依次排序即可得到该情节的任务分配工作序列,由奖励功能定义可知,累积奖励最大的工作序列具有最短的工作时长,为最优任务分配方案。
4实验与讨论
为了验证任务分配环境以及所提出改进算法的有效性,我们在两个不同难度的分配任务中,对DQN和存档机制改进算法ArchiveDDQN(rchiveDQN和ArchiveRDQN)进行了训练和测试。实验中,三种算法均使用文献[2提供的深度神经网络,通过两个网络分别学习目标函数。
5结束语
本文提出了一种基于深度强化学习的人机协作组装任务分配方法,以适应人机协作任务分配日趋复杂的任务结构和高维的任务空间。本文的贡献和创新点主要有两点:
(1)将人机协作组装任务分配形式化为强化学习问题,并构建了通用化的组装闯关游戏模拟环境,使得高维复杂的任务分配问题可以便捷地使用深度强化学习方法进行求解;(2)提出了存档机制及其改进算法ArchiveDDQN,解决了传统DQN系列算法情节频繁重启的问题,进一步提升了算法的性能和人机协作组装任务分配的稳定性。在两种不同难度的实验环境中,普通模式存档机制均能有效提升DQN算法的训练速度和训练效果。
在通关模式下,存档机制得到了更好的发挥,使得DQN算法获得了优秀的全局探索能力和测试稳定性。实验证明了所提出的人机协作组装任务分配方法的有效性。在未来的工作中,将考虑更复杂的场景,如多个组装任务的混合执行和人类行为的不确定性等。在进一步拓展所提出算法工业应用的同时,将考虑采用更先进的技术去减少计算量和提升训练效率。
参考文献:
[1]ROBLAGOMEZS,BECERRAVM,LLATAJR,etal.Workingtogether:Areviewonsafehumanrobotcollaborationinindustrialenvironments[J].IEEEAccess,2017,5:2675426773.
[2]WANGL,GAOR,VANCZAJ,etal.Symbiotichumanrobotcollaborativeassembly[J].CIRPAnnalsManufacturingTechnology,2019,68(2):701726.
[3]ZACHARAKIA,KOSTAVELISI,GASTERATOSA,etal.Safetyboundsinhumanrobotinteraction:Asurvey[J].SafetyScience,2020,127:104667.
[4]LIHao,LIUGen,WENXiaoyu,etal.Industrialsafetycontrolsystemandkeytechnologiesofdigitaltwinsystemorientedtohumanmachineinteraction[J].ComputerIntegratedManufacturingSystems,2021,27(2):16(inChinese).[李浩,刘根,文笑雨等.面向人机交互的数字孪生系统工业安全控制体系与关键技术[J].计算机集成制造系统,2021,27(2):16.]
[5]SARA,JENSEN.TheIndustrialInternetofThings[J].OEMOffHighway,2016,34(7):2022.
作者:熊志华1,陈昊2,王长生1,岳明1,侯文彬1,3,+,徐斌2
最新期刊论文咨询
- 浏览量:331教育期刊当前外语翻译教育教学面临的问题及对策
- 浏览量:370“互联网+”背景下石化类高职教育高质量发展的思考
- 浏览量:364手机媒体对高职教师课堂教学的影响力
- 浏览量:327如何加强技工学下职业道德教育
- 浏览量:415高新技术企业申报中创新能力对研发费用的处理
- 浏览量:336以德律学―论师德对于防范教学事故的意义
- 浏览量:359高中地理教学中如何渗透生态文明教育
- 浏览量:336翻转课堂教学模式在地理教学中的应用
- 浏览量:3195-6 岁学龄前儿童参与式产品设计方法研究
- 浏览量:276网络英语课程学习平台用户资源云共享安全性研究
SCI核心期刊推荐
-

-
Scientific Reports
数据库:SCI
ISSN:2045-2322
刊期:进入查看
格式:咨询顾问
-

-
ACTA RADIOLOGICA
数据库:SCI
ISSN:0284-1851
刊期:进入查看
格式:咨询顾问
-

-
Materials Today Communications
数据库:SCI
ISSN:2352-4928
刊期:进入查看
格式:咨询顾问
-

-
PLANT JOURNAL
数据库:SCI
ISSN:0960-7412
刊期:进入查看
格式:咨询顾问
-

-
APPLIED SURFACE SCIENCE
数据库:SCI
ISSN:0169-4332
刊期:进入查看
格式:咨询顾问